Voice is great for getting quick answers to simple questions. Visuals are great for more complex tasks. So what happens when you combine the two? At the Chatbot Summit in Berlin, Google offered its insights into ‘multimodal’ bot interfaces. Tim Green took notes.
Across 2017 and and 2018 Amazon and Google did something that changed the game for chatbot designers. They added screens to their voice assistants.
Amazon’s Echo Show and Google’s Home Hub turned what had been smart speakers into something else – machines you could read/browse and well as talk/listen to.

This was an important moment. Amazon and Google had won credit for developing the first new communications platform since the smartphone. Their smart speakers won over the critics and the public. All of a sudden it became acceptable to shout questions to an inanimate machine in your kitchen.
Yes, there had been smartphone voice search (Siri and Google Assistant and Cortana) before them, but Echo and Home really consolidated the idea of machines that listen.
So the addition of screens moved the goalposts. It challenged developers (and conversation designers) to re-think their interactions with users/customers.
Specifically, it challenged them to be multimodal.
Instead of thinking about the best way to answer a question in speech, they now have to consider how best to do it by combining speech with visuals and even touch.
The good news is that Google has been thinking about multimodal interfaces for years. Why? Probably because of Google Assistant.
Google Assistant is, of course, the service that anticipates a user’s needs. It analyses various sources (calendar, maps, email, browsing habits etc) to present relevant information. For example, it will remind you of a flight booking and suggest the best route from where you are.
Android users can activate Google Assistant on the phone. They can talk to it and/or look at visual information.
But Google has always been clear that Assistant will eventually live on other ‘surfaces’: wearables, car, TV and more.
At last month’s Chatbot Summit in Berlin, Jared Strawderman, multimodal design manager at Google, shared some key insights into how developers and brands should think about multimodal interfaces.
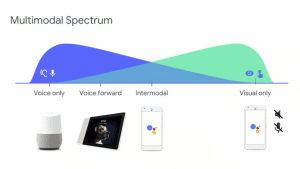
He started by looking at the different properties of the various devices. He suggested developers should ponder the following questions when designing interfaces and conversations.
- Is the device private or public?
- Is the device conceived for one to one interactions or shared use?
- What is the user’s proximity to the device? There’s a big difference between a phone in the pocket and a TV on the wall
- What is the quality and quantity of the input? Does it have multiple microphones and cameras?
- What is the quality and quantity of the outputs? Does it have a screen? Is it hi-res?
Context matters too. For example, there might be a hi-res display on an in-car device, but for obvious reasons designers should build for voice in this environment.
Strawderman then dug into the pros and cons of voice and visual communications.
Advantages of voice interface
This is the equivalent of a screen showing a fast-moving ticker and expecting the reader to remember it all,’ he said. “It’s better to read out the top three films and then ask ‘would you like to hear more’ while showing the complete list on screen.”
- It’s direct.
- It’s universal. There’s no training manual needed. Everyone knows how to talk.
- It’s quick – but only when you know exactly what you want
- It’s good for when the hands and eyes need to be elsewhere (eg when cooking)
Disadvantages of voice interface
- It’s bad at complexity.
- It’s ephemeral. Voice is gone as soon as it is spoken, so it’s not east to revise an answer.
- It’s public. It is unsuitable in some scenarios
- It doesn’t permit navigation
- It demands attention. The user can’t deflect attention.
Advantages of visual interface
- It’s permanent and browsable. Users can easily revise answers and review material. They can drift in and out.
- It’s private and discreet compared to voice.
- It’s fast (at complex tasks)
Disadvantages of visual interface
- It demands some technical competence. Users have to understand menus etc.
- It is slow (when a simple answer is sought).
- It is indirect – the user has to do most of the work.
Strawderman said developers should factor in all of the above while designing their dialogues. And he suggested some workarounds for common scenarios.
For example, let’s say a person enquires about cinema showings. It would be ridiculous for a smart speaker to simply read out all the options.
“This is the equivalent of a screen showing a fast-moving ticker and expecting the reader to remember it all,’ he said. “It’s better to read out the top three films and then ask ‘would you like to hear more’ while showing the complete list on screen.”
But why bother with voice at all? Why not just show the listings? Well, Strawderman added that developers should always design with the presumption that one mode could go away. This could be for technical or social reasons.
As tech users, we have become so used to browsing windows, scanning menus and clicking on icons. We’re just now getting familiar with voice. It seems certain that we will soon learn to combine the two. A bit like real life.




